Introduction to HTML
Hypertext Markup Language (HTML)](https://en.wikipedia.org/wiki/HTML) is the standard markup language for documents designed to be displayed in a web browser. It can be assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.
Web browsers receive HTML documents from a web server or from local storage and render the documents into multimedia web pages. HTML describes the structure of a web page semantically and originally included cues for the appearance of the document.
To get the desired data, we need to know the structure of the specific website.
Web Source of Zhihu
-
Zhihu is a Chinese question-and-answer website where questions are created, answered, edited and organized by the community of its users. It’s quite like the English one Quora.
-
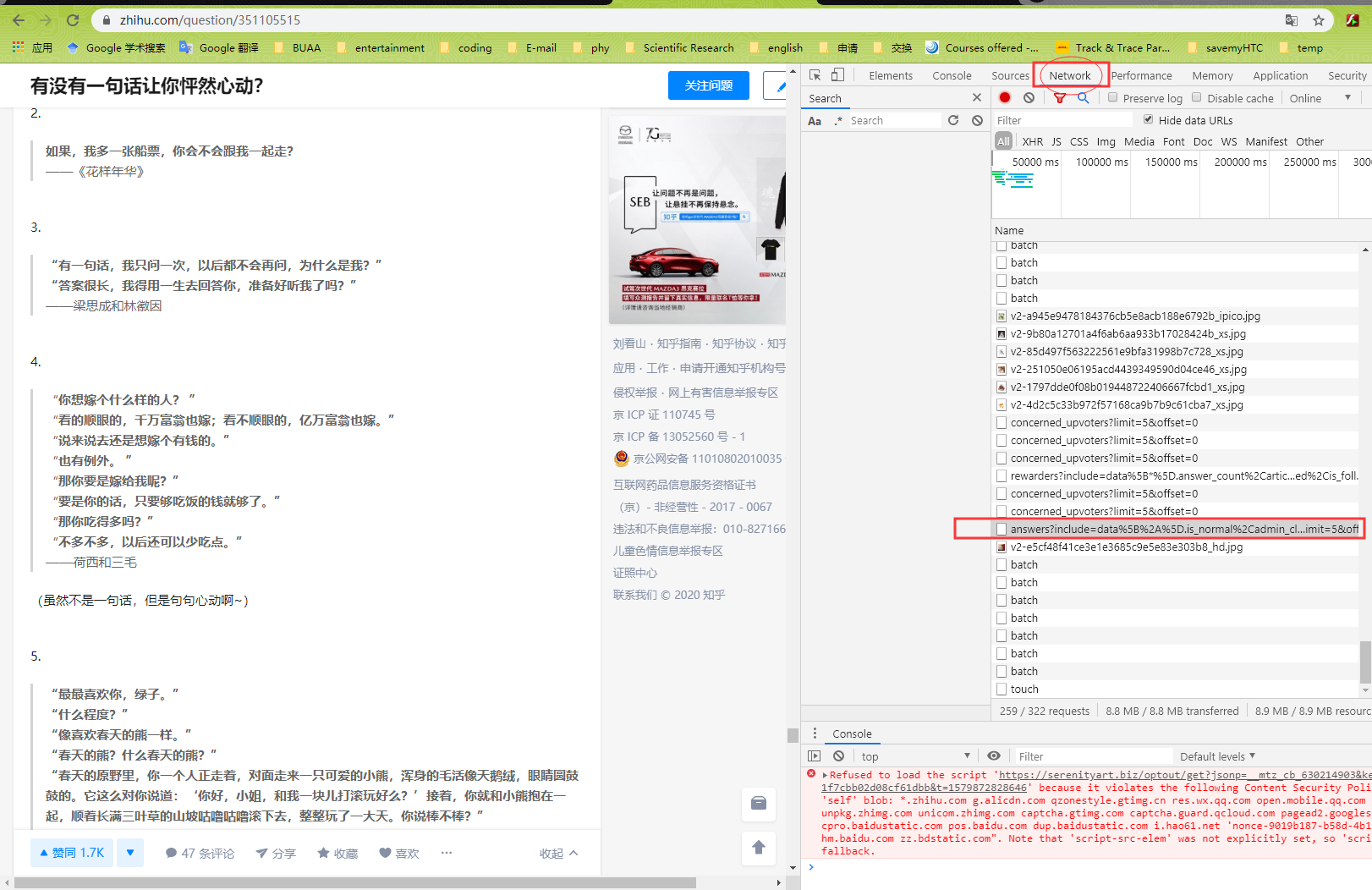
Open develop tools in the browser in a Zhihu question webpage.
-
You can find a file in the Network the new url direct to the new answers when you browse down to get new answers.
-
You get the url like (for example):
[https://www.zhihu.com/api/v4/questions/351105515/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=13&platform=desktop&sort_by=default](https://www.zhihu.com/api/v4/questions/351105515/answers?include=data[*].is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata[*].mark_infos[*].url%3Bdata[*].author.follower_count%2Cbadge[*].topics&limit=5&offset=13&platform=desktop&sort_by=default)In this url, by comparing several this
answerurl, you will notice that the only difference is thequestion id351105515, limit and offset.limit sets the number of answers loaded by this url, offset sets the location of the first answer in this url. Apparently, all of these answers are well sorted.
Now we know how the answers in a specific question are structured, the next step is to using Python code do it automatically.
Python Code
I write the code in Jupyter, you can download the file here.
The main point here is to using function get in requests package to send request and get the html source back from the server. Then Using package BeautifulSoup4 to prettify the source and using find function to find the tag we are interested.
The data/information we are interested is just buried in some of these tags transferred back from the server. We can find them and get the new answers and the repeat this process over and over again. That all we need to do this time.
Bonus: Get the Hidden Content of Zhihu Article
Some times the content of a Zhihu article can be hidden, so we need to get the original content.
Here is what a hidden post looks like:
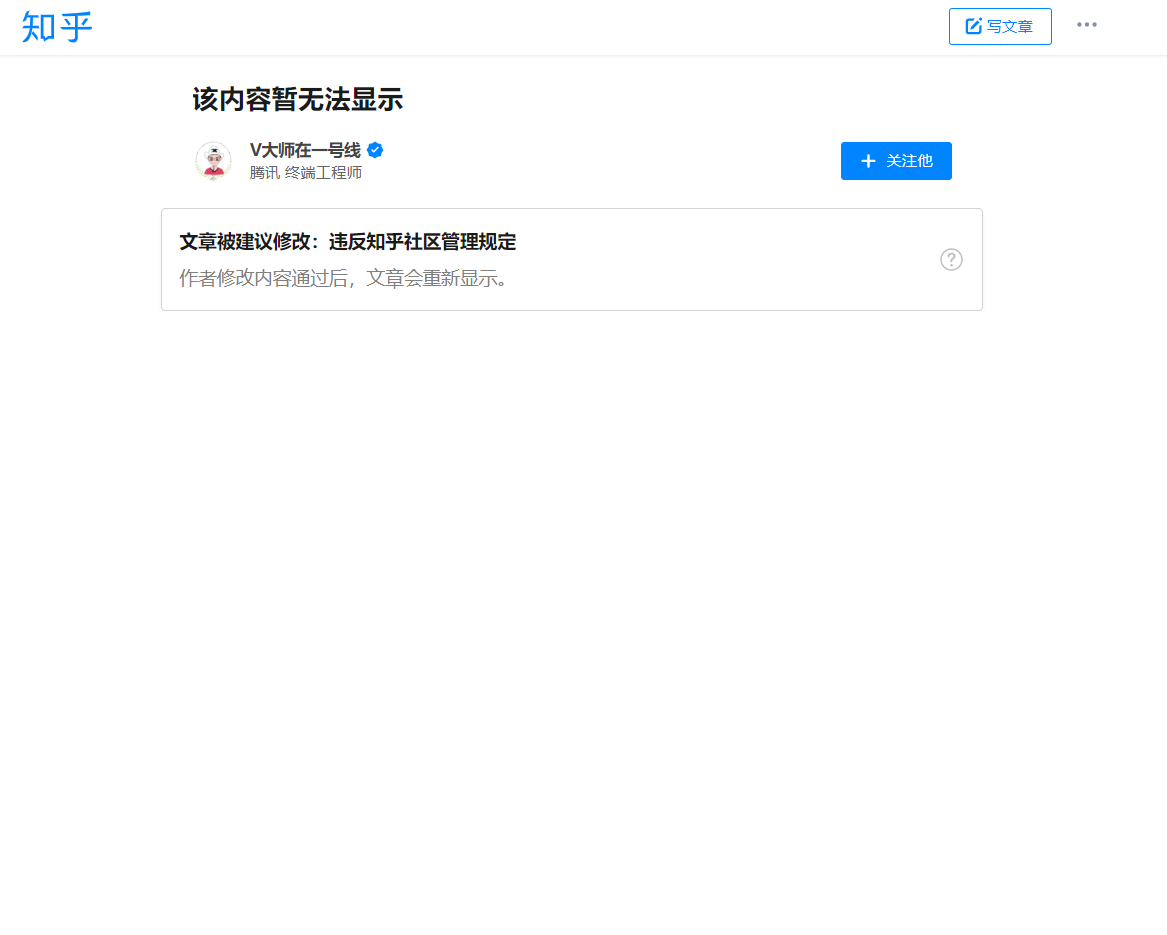
By looking up the source code of this webpage, we find that the original content is hidden in the form of json, and we should transform it back and replace the trash part.
The Jupyter notebook file is here
After that process, we can get the original content like this: