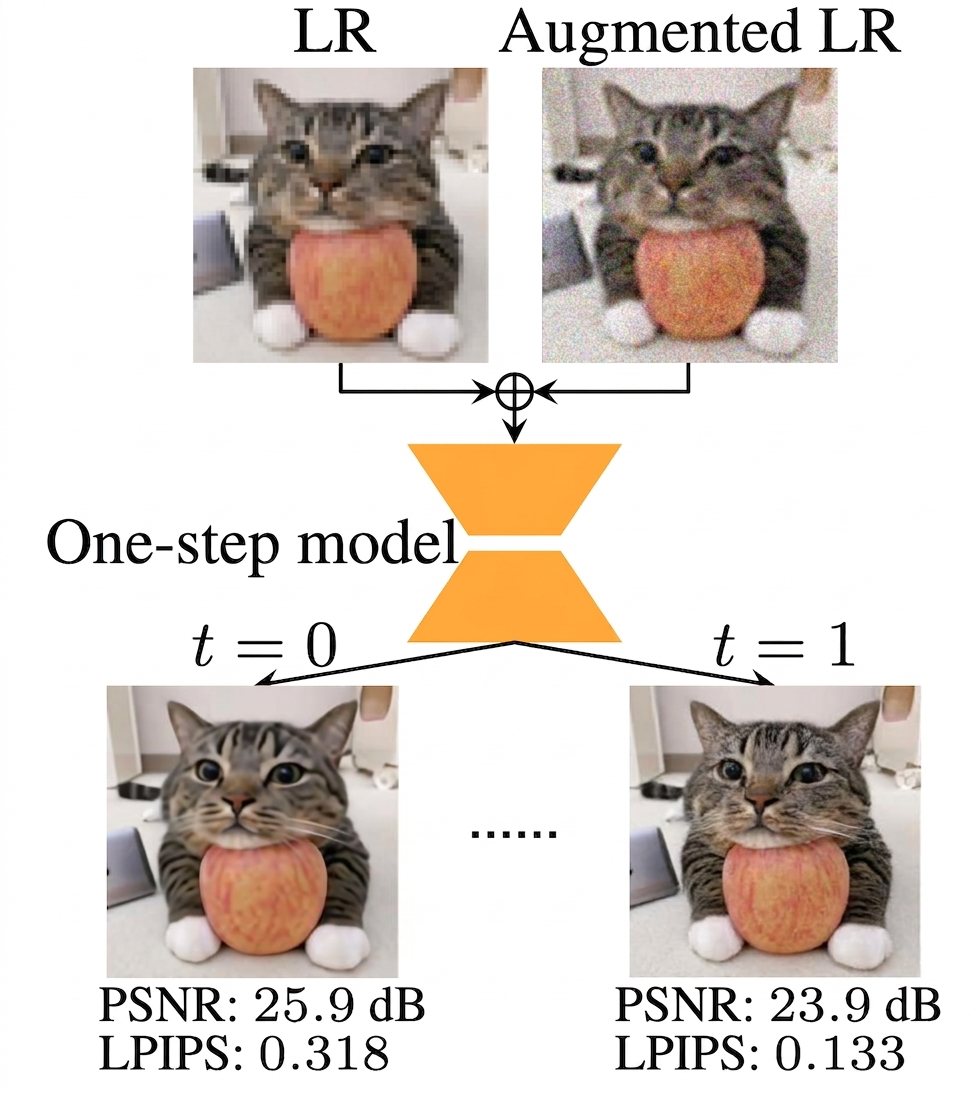
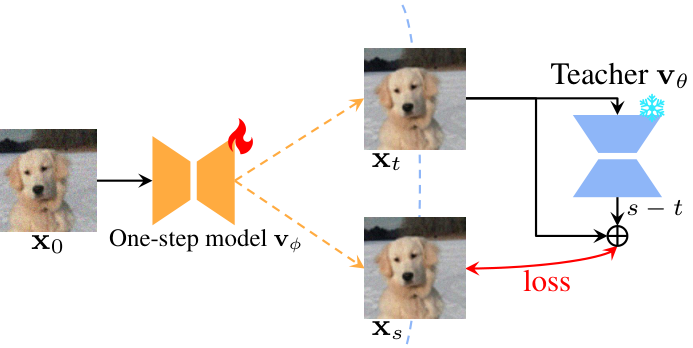
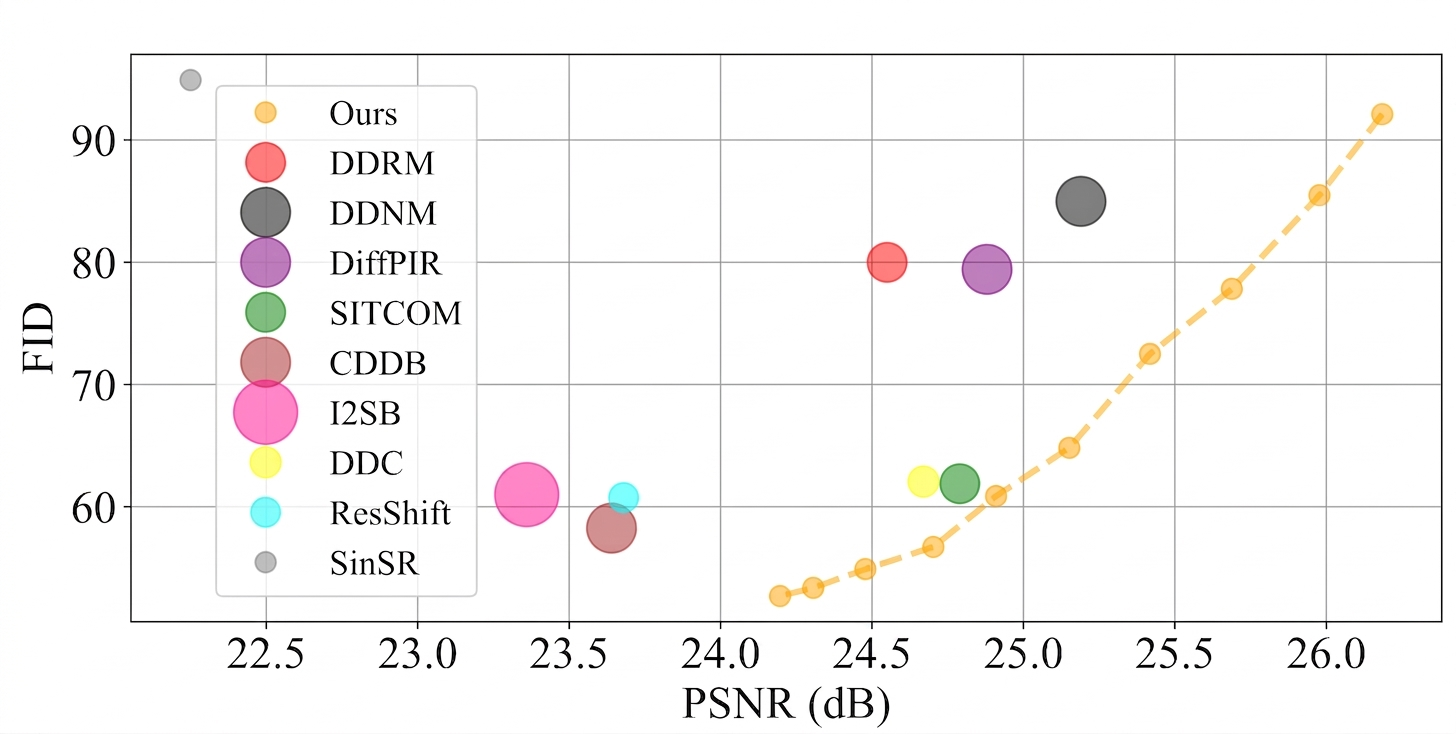
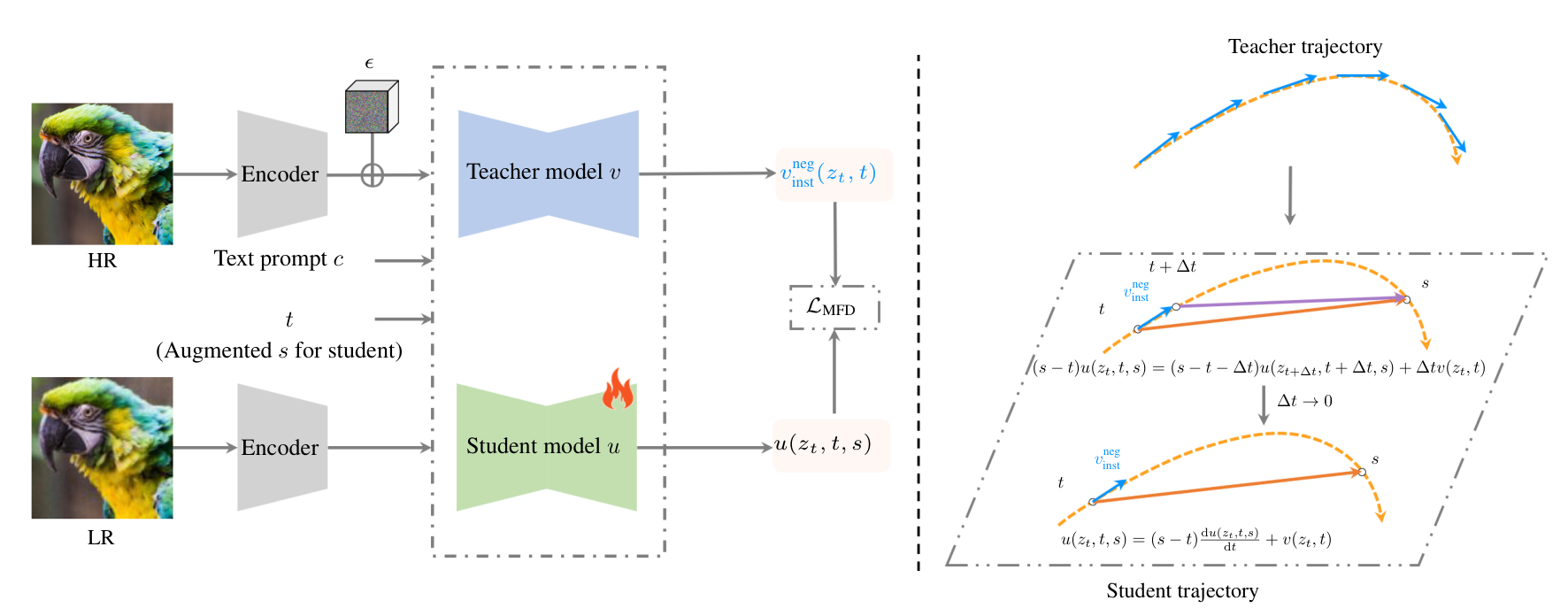
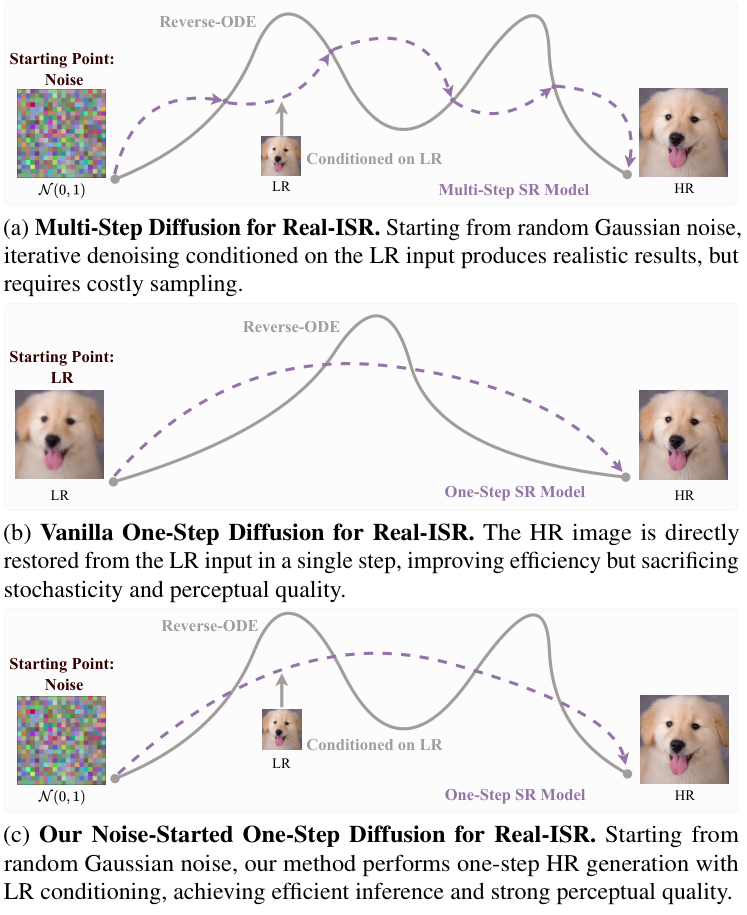
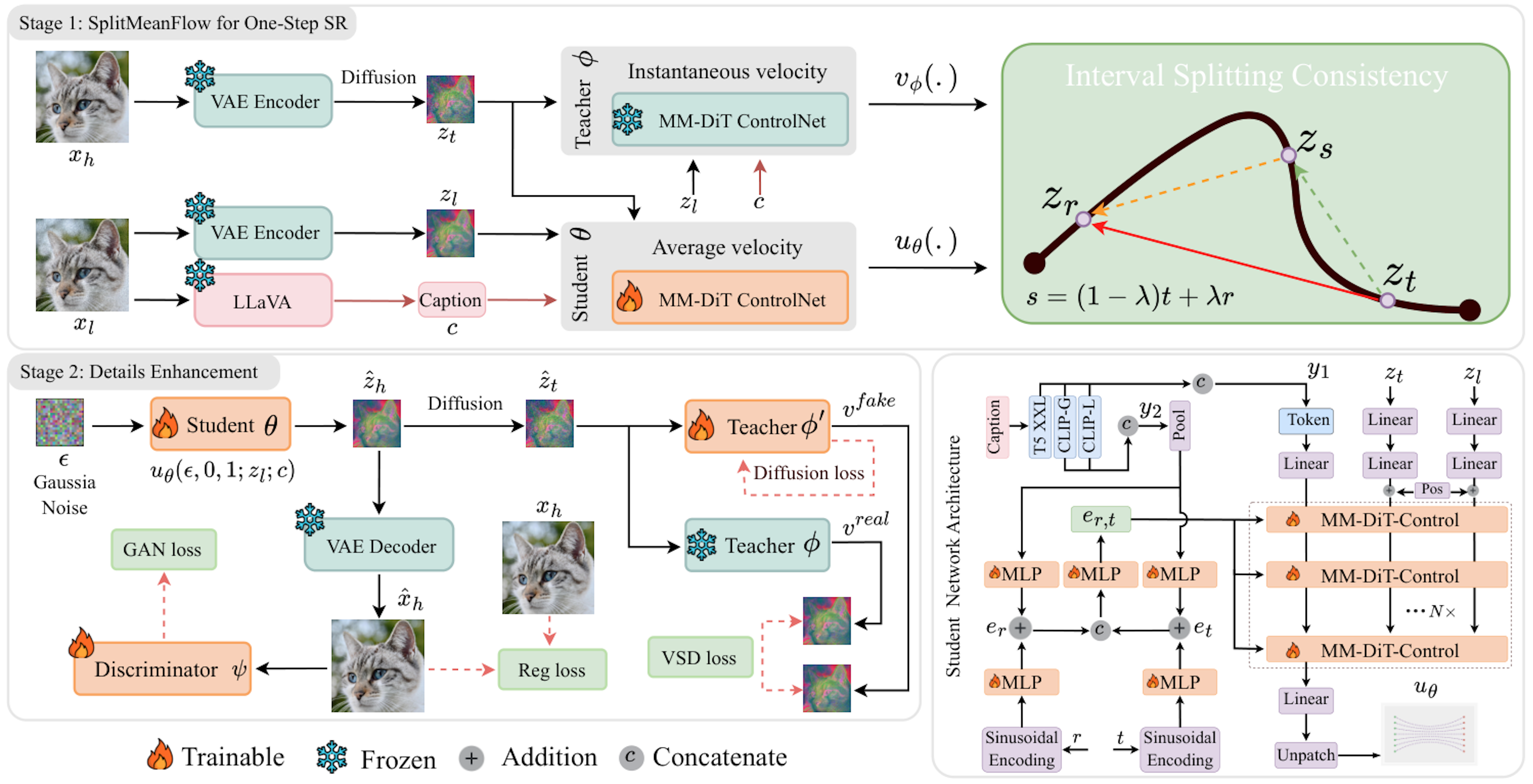
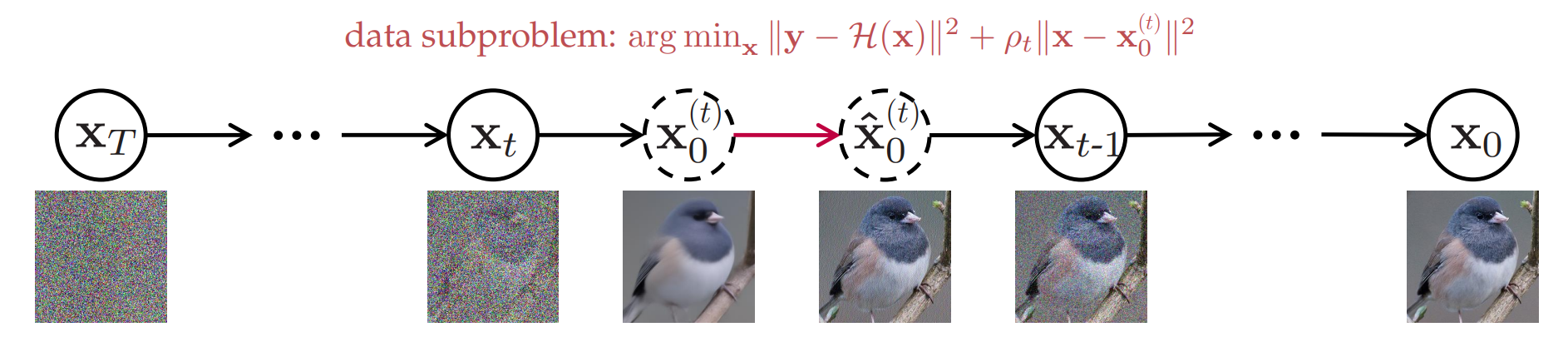
DiffPIR Denoising Diffusion Models for Plug-and-Play Image Restoration
Yuanzhi Zhu, Kai Zhang, Jingyun Liang, Jiezhang Cao, Bihan Wen, Radu Timofte, Luc Van Gool
- →General framework for SR, deblurring, inpainting
- →Training-free: no task-specific training, just an off-the-shelf diffusion model
- →Strong perceptual quality on FFHQ & ImageNet