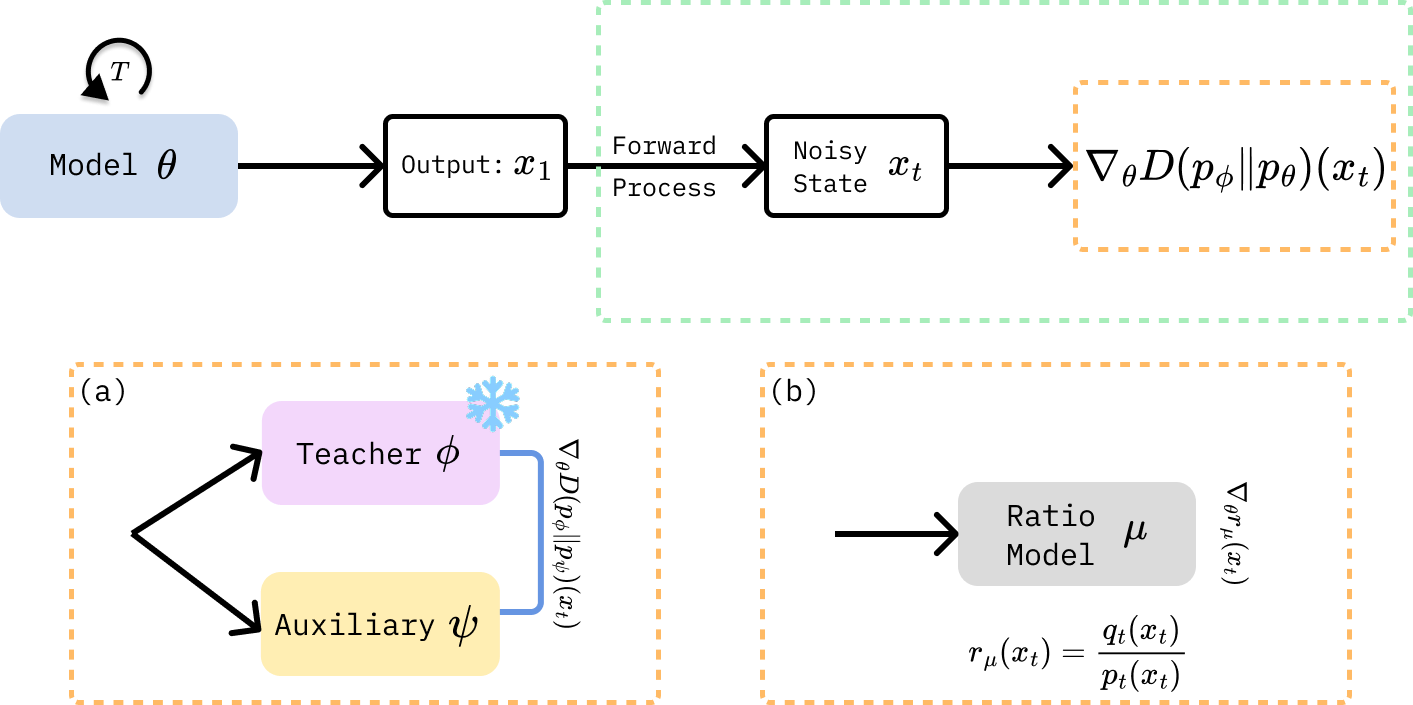
p = empirical data; D = KL
→ maximum likelihood estimation
// Research Talk · April/2026
Distillation as
Divergence Minimization
$$\min_{\theta} \; \mathbb{E}\!\left[ D\!\left( p_{\text{target}} \,\|\, p_{\theta} \right) \right]$$

Di[M]O · arXiv:2503.15457
Di-Bregman · arXiv:2510.16983
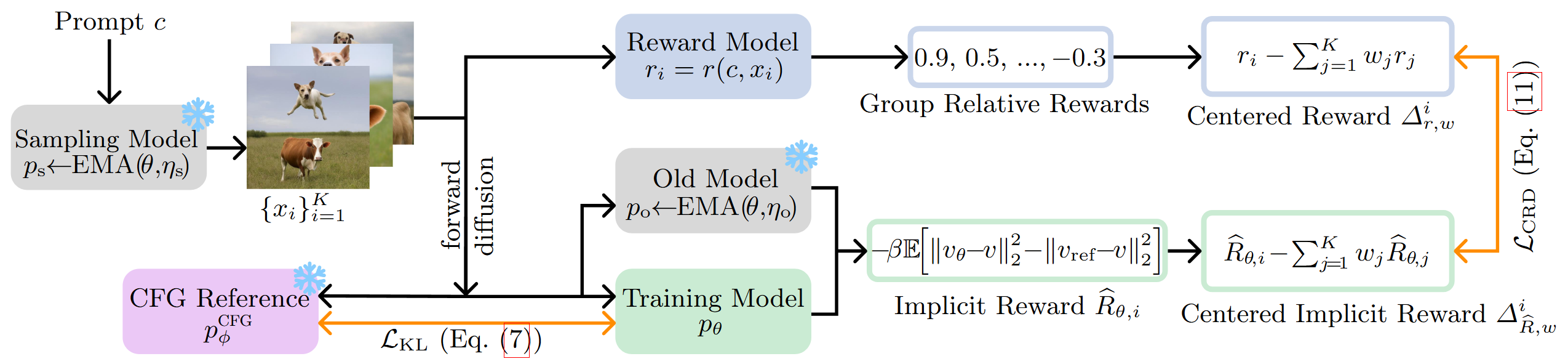
CRD · arXiv:2603.14128